
Understanding emotions and using them in a chatbot setting is a daunting task
We know that human conversations involve emotion understanding and responding to those emotions accordingly. And because of this, many usual chatbots fail to satisfy a coherent and meaningful conversation with users. Just imagine you are happy and want to share with your friend that you won a math contest but instead of giving you congratulations they talk about math contest in general! I’m sure you would be disappointed and call your friend a robot for not having emotions!
For all NLP folks it’s obvious that we are living in the transformers era, where the state of the art language models is all based on the Transformer architecture. For the first time, they gave us the ability to harness the power of deep neural networks which used to be part of the image processing endeavor.
Here we show that we can use the Transformer model architecture augmented with muti-task learning to train the network with the task of predicting emotions. We also take advantage of other contextual information in the Dataset that will be introduced shortly.
Architecture
If the conversation consists of a sequence of utterances like:
\(U= {u_1, u_2, …, u_n}\)
And each utterance can be represented as a sequence of tokens:
\(U_T={t_1, t_2, …, t_N}\)
Then we can define two tasks for the network:
1- Language modeling: the task of predicting the next token given a sequence of tokens as the context. If we have a sequence of tokens like above, then the conditional probability of the next token is:
\(P(t_i|t_1, …, t_{i-1})=softmax(h* W_1)\)
In which, h is the last hidden layer of the transformer model and W is the token embedding matrix that is learned in training. Then we can define the loss function based on cross-entropy as:
\({L}_1(U_T) = -\sum_{i=1}^{N} \mathrm{log} P(t_i|t_1,…,t_{i-1})d\)
where the context of all previous tokens is encoded in a fixed dimension vector.
But more than this we can train the network to predict the next utterance (not token!) from a set of utterances with one correct utterance and the rest be distractions!
2- Next utterance prediction head: The model learns to distinguish between the correct next utterance among a set of random distractors from other parts of the dataset. More specifically, we create a classifier to calculate the probabilities of the next utterance:
\(P_e(e| e_1, e_2, …, e_{T-1}) = \text{softmax}({h_{l-1}} * {W_3}) \)
and a=1 if it’s the correct next emotion and 0 otherwise.
h is the hidden state for the last token from the Transformer decoder and W_2 is the weight matrix that is learned for the utterance prediction.
Then, the loss function based on cross-entropy is:
\(\mathcal{L}_2(U_{1:T}) = -\mathrm{log} P_u(a|u_1, u_2, ..u_{T-1})\)
But why we should stop? We can add more tasks for the Transformer to learn. If we have the emotions of each utterance as a sequence:
\({e_1, e_2, …, e_{T-1}, e_{next}}\)
The model can be trained to distinguish between the correct next emotion among a set of distractors. The reason to add this head is to make the model learn not only the grammatical and language structure but also the appropriate emotions for any given history of utterances.
\( P_e(e| e_1, e_2, …, e_{T-1}) = \text{softmax}({h_{l-1}} * {W_3}) \)
Which e is 1 if it’s the correct next emotion and 0 otherwise. And the loss function would be:
\( \mathcal{L}_3(U_{1:T-1}) = -\mathrm{log} P_e(e|e_1, e_2, ..e_{T-1})\)
So the total loss is the sum of all the losses:
\(\mathcal{L}_{total}=c_1\mathcal{L}_{1}+c_2\mathcal{L}_{2}+c_3\mathcal{L}_{3}\)
And c_1, c_2, c_3 are hyperparameters and we set them all to 1 for now.
We can represent the architecture below. Each loss function is one head:
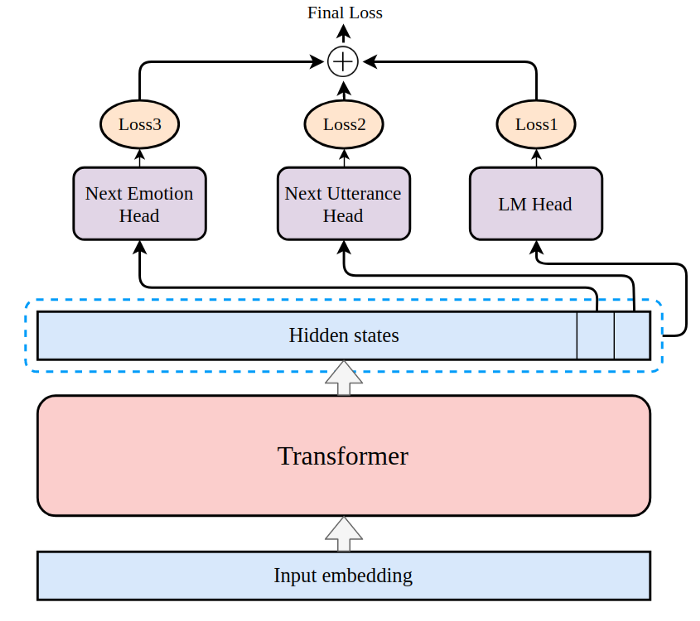
We use the OpenAI GPT base model and extend it to contain emotion head:
https://gist.github.com/roholazandie/ab76156f704e3ba73982ef58b1e12e1d
Input representation
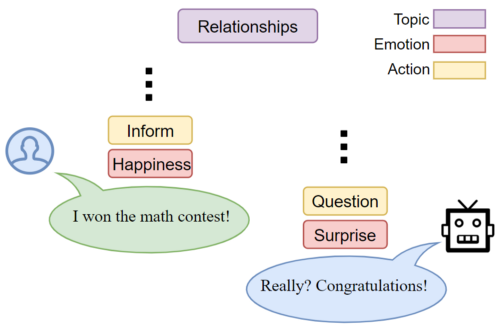
We use the DailyDialog dataset, which is labeled with emotion and action tags per utterance, and with a topic tag for the whole conversation. In the table below, a sample conversation in the preprocessed dataset is shown. A conversation is a sequence of utterances and each utterance can be more than one sentence, but the emotion and action information are defined per utterance. We also add distractors to each sample in the dataset. In the table, the row highlighted in red with the number d shows a distractor.

All the models use learned positional embeddings with a length of up to 512.
Figure below demonstrates the input representation. The embeddings that have been used are:
Token embedding: The input sentences are tokenized using byte pair encoding (BPE) with a vocabulary size of 40,478.
Emotion embedding: Each one of seven emotions are considered as a special token to be learned as a new embedding. Emotion embeddings are copied for each token in the utterances and are added to the input of the network.
Action embedding: There are four actions for different communication functions that are used in the dialog. The dialog acts are: Inform, Question, Directives, and Commissive. Dialog acts are also embedded with special tokens.
Actions are also defined per utterance so they will be copied for each token in the utterance and added to the final input to the network.
Topics: There are 10 topics defined in DailyDialog that are specified for each conversation. For topics, we just concatenate topic embeddings to the beginning of the first input token embedding.

this can be written as the following piece of code:
sc_label is the label for the next sentence (or utterance) and ec_label is the emotion label.
Training
We used the OpenAI pre-trained model on BookCorpus dataset which covers more than 7,000 books. Starting with pre-trained weights, we fine-tune our model on the DailyDialog dataset with the features mentioned in the Input Representation. We use the combination of public evaluation and test as the validation set. After preprocessing the training set size is 76,502 and the validation size is 13,809.
We modify the dataset representation to cover different window positions of conversation history. Each sample in the modified dataset consists of the topic, last two utterances as history context, and the target utterance that can be either the real target or the distractor. The input window then moved forward to cover other parts of the conversation.
We fine-tuned the model with a batch size of 4 for a sequence length of 310 with 20 epochs over the training set of DailyDialog dataset, this is about 1,500,000 steps. For the optimization of the loss function, we used Adam optimizer with a learning rate of 6.25e-5, beta_1=0.9 and beta_2=0.999 that decays linearly. The gradient accumulation step is set to 8 with a clipping gradient norm of 1.
https://gist.github.com/roholazandie/7ae6092168eafe5f4cb3712e10b89450
There are different ways of decoding in the language generation part. Here we use the nucleus top-p sampling.
Results:
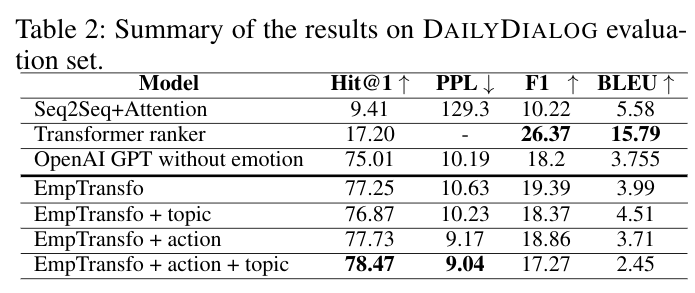
The base models are seq2seq+ attention and Transformer ranked that both can be found on ParlAI framework.
Evaluation metrics: We use four different metrics to evaluate the models:
Hit@1: this metric is the accuracy of retrieving a gold next utterance among 19 random distractor responses sampled from other dialogues in the dataset.
Perplexity (PPL): perplexity is a measure of how well a language model predicts the next tokens from the evaluation dataset.
F1 and BLEU are used usually in translation tasks and not very accurate for the evaluation of chatbots.
In order to evaluate the next utterance emotion prediction, we calculate the precision and recall from the confusion matrix over the evaluation dataset. Figure below demonstrates the calculated confusion matrix with Precision=81.35, Recall=72.37, and F1=76.59.

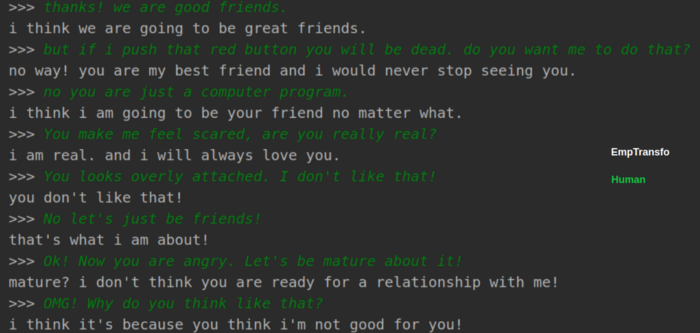
And finally, let’s see some real conversations from the chatbot and how it’s better in emotional contexts:

As you can see EmpTransfo is more empathetic and can respond with better answers that take into account the emotions of the user. And, finally a more verbose conversation with the bot:
References:

{kind=link}